Idempotence : du concept mathématique à la fiabilité des systèmes critiques
Elevators, vous appuyez frénétiquement sur le bouton d’un ascenseur déjà allumé. Pourtant, l’ascenseur n’est pas appelé plusieurs fois. Félicitations, vous venez d’expérimenter l’idempotence dans le monde réel!
Ce concept, simple en apparence, est une discipline d’ingénierie indispensable pour garantir l’intégrité des données et la fiabilité des opérations dans les systèmes distribués. Cet article va au-delà de la définition de base pour explorer les défis d’implémentation, les alternatives et les compromis que tout développeur ou architecte doit maîtriser.
Qu’est-ce que l’idempotence ? Un Rappel Essentiel
L’idempotence trouve son origine en mathématiques, où une opération est dite idempotente si des applications répétées ne changent pas le résultat au-delà de l’application initiale. La formule est simple :
f(f(x))=f(x)
En informatique, le principe est le même : une opération est idempotente si l’exécuter une ou N fois produit exactement le même résultat et les mêmes effets de bord. Dans un monde d’architectures microservices où les pannes réseau, les timeouts et les rejeux automatiques sont inévitables, cette propriété n’est pas un luxe, mais une nécessité.
Pourquoi l’idempotence est-elle cruciale ?
La plupart des courtiers de messages modernes (Apache Kafka, RabbitMQ, Amazon SQS, Google Pub/Sub) proposent une garantie de livraison dite « au moins une fois » (at-least-once). Pour ne jamais perdre de données, le système préfère renvoyer un message en cas de doute, créant un risque de duplication.
Sans idempotence, ces doublons peuvent avoir des conséquences désastreuses dans de nombreux domaines :
- Fintech : Un virement bancaire traité deux fois, débitant un client en double.
- E-commerce : Une commande unique confirmée et expédiée plusieurs fois, entraînant des pertes de stock et une mauvaise expérience client.
- Logistique : Un événement de « colis livré » traité en double, créant des incohérences dans le système de suivi.
- Réseaux Sociaux : Un événement « like » dupliqué qui fausse les métriques d’engagement.
L’idempotence dans un système de messagerie distribué(Ex. Kafka) : un garde-fou contre les doublons
Apache Kafka, en tant que système de messagerie distribué, est particulièrement exposé aux risques de duplication de messages. Kafka introduit donc des mécanismes pour garantir le caractère idempotent côté producteur.
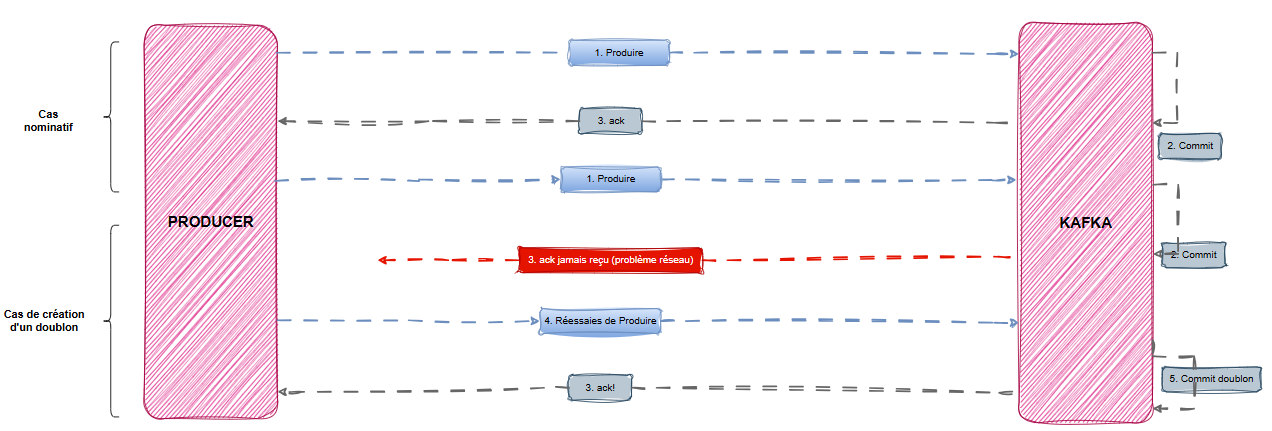
Côté producteur : une garantie native
Depuis Kafka 0.11, la propriété idempotente du producteur est activable via une simple configuration (enable.idempotence=true). Depuis Kafka 3.0, le caractère idempotent du producteur est activé par défaut (enable.idempotence=true et acks=all) 👉🏽 KIP-679 Cela permet à Kafka de :
- Détecter les doublons via un Producer ID (PID) et un sequence number
- Éviter les insertions multiples du même message dans une partition
Mais cela ne couvre qu’une partie du problème…
Et le consommateur alors ? L’angle mort de l’idempotence
Kafka ne garantit pas l’idempotence côté consommateur. Cela signifie que :
- Un message peut être consommé plusieurs fois (ex. : après un crash ou un rebond de consumer group ou une anomalie applicative)
- Le traitement métier peut être réexécuté, avec des effets secondaires potentiellement graves
💬 La proposition de Chris Richardson (microservices.io)
Chris Richardson recommande de rendre les consommateurs eux-mêmes idempotents, en appliquant des stratégies autour de :
- Détection de doublons via un identifiant unique de message stocké dans une base
- Stockage de l’état avant traitement
- Utilisation de transactions pour garantir l’exactitude
Implémentation : Le Pattern du Consommateur Idempotent
La stratégie la plus courante pour gérer les doublons est de rendre le consommateur de messages lui-même idempotent. Le principe consiste à tracer les messages déjà traités.
- Identifier : Extraire un identifiant unique et stable du message (par exemple,
eventId,transactionId). - Vérifier : Consulter un stockage de données transactionnel (base de données, cache distribué) pour voir si cet ID a déjà été traité.
- Exécuter (ou ignorer) :
- Si l’ID existe, le message est un doublon et doit être ignoré. L’opération se termine avec succès.
- Si l’ID est nouveau, le traitement métier est exécuté. L’ID du message est ensuite stocké dans la même transaction atomique que la modification des données métier.
Ce diagramme illustre le flux : un message arrive, son ID est vérifié. S’il est nouveau, il est traité et son ID est enregistré. Si un doublon du même message arrive plus tard, la vérification de l’ID permet de l’ignorer instantanément, préservant ainsi l’intégrité du système.
Pseudo-code d’implémentation
Voici un exemple en Java illustrant ce pattern.
public void processEvent(Event event) {
// On démarre une transaction avec la base de données
Database.beginTransaction();
try {
// Étape 2 : Vérifier si l'ID a déjà été traité
if (processedEventRepository.existsById(event.getEventId())) {
log.info("Event {} already processed, skipping.", event.getEventId());
} else {
// Étape 3 : Traiter le métier ET enregistrer l'ID
businessService.handleBusinessLogic(event.getData());
processedEventRepository.save(new ProcessedEvent(event.getEventId()));
log.info("Event {} processed successfully.", event.getEventId());
}
// Tout est OK, on valide la transaction
Database.commitTransaction();
} catch (Exception e) {
// En cas d'erreur, on annule tout
Database.rollbackTransaction();
log.error("Error processing event {}. Rolling back.", event.getEventId(), e);
throw e; // L'erreur est propagée pour que le message soit retraité plus tard
}
}Ce pattern est universel. En Python, il peut être implémenté avec un décorateur ; en Go, avec un middleware, etc . L’essentiel est de lier la vérification de l’ID et le traitement métier dans une unité de travail atomique.
Les Défis Techniques en Pratique
L’implémentation de ce pattern soulève deux défis majeurs :
- Génération d’identifiants uniques : La fiabilité du système repose sur un identifiant unique et déterministe. Utiliser des UUID (v4 ou v7) générés par le producteur est une approche robuste. Cependant, dans des systèmes complexes, garantir l’unicité sans point de contention peut devenir un défi d’architecture.
- Impact sur la performance : Chaque message induit une lecture (
SELECT) et potentiellement une écriture (INSERT) supplémentaires dans la base de données pour vérifier l’ID. Sur des systèmes à très haut débit, cela peut devenir un goulot d’étranglement. Une optimisation consiste à utiliser un cache rapide comme Redis pour le « check », tout en s’assurant que l’écriture finale reste atomique avec la logique métier.
Alternatives et Approches Complémentaires
Le consommateur idempotent n’est pas la seule solution. D’autres approches existent :
- Sémantiques Exactly-Once (EOS) : Des plateformes comme Apache Kafka proposent des garanties EOS. C’est une solution puissante mais complexe, qui requiert que chaque composant de la chaîne (producteur, broker, consommateur) participe au protocole transactionnel. Elle est souvent plus rigide et peut avoir un impact sur la performance.
- Déduplication côté courtier : Certains services, comme Amazon SQS FIFO (First-In, First-Out) queues, offrent une déduplication automatique basée sur un ID de déduplication fourni avec le message, valable pendant une fenêtre de 5 minutes. C’est une solution simple et efficace pour des scénarios de rejeux rapides.
- Clés d’Idempotence dans les APIs REST : Pour les interactions synchrones, le pattern
Idempotency-Keydans les en-têtes HTTP est une norme de facto. Le client génère une clé unique, et le serveur l’utilise pour s’assurer qu’une requêtePOSTouPATCHn’est exécutée qu’une seule fois.
Les Compromis à Considérer
Implémenter l’idempotence a un coût. Il est crucial d’évaluer les compromis :
- Complexité du code : La logique de gestion des doublons ajoute une couche de complexité au code applicatif.
- Coûts de stockage : Le stockage des ID de messages traités consomme de l’espace et nécessite une stratégie de purge pour éviter une croissance infinie.
- Latence : L’appel supplémentaire à la base de données ou au cache pour chaque message augmente légèrement la latence de traitement.
L’idempotence est-elle toujours nécessaire ? Pas toujours. Pour des opérations non critiques comme l’ingestion de logs ou des notifications sans impact financier, une approche plus simple peut suffire. La règle d’or est d’évaluer le coût d’un doublon par rapport au coût de l’implémentation de l’idempotence.
Conclusion : Au-delà du Buzzword, une Pratique d’Ingénierie
L’idempotence n’est pas une solution magique, mais une pratique d’ingénierie réfléchie. Elle transforme des opérations potentiellement chaotiques en processus fiables et prévisibles. Pour les architectes et développeurs de systèmes distribués, la question n’est pas si il faut gérer les doublons, mais comment le faire de la manière la plus adaptée au contexte. En maîtrisant ces patterns et leurs compromis, vous construisez des applications non seulement fonctionnelles, mais véritablement robustes.
Pour Aller Plus Loin
- Pattern Idempotent Consumer : microservices.io par Chris Richardson
- Kafka’s Exactly-Once Semantics : Documentation officielle d’Apache Kafka
- Idempotence pour les APIs REST par la Chancellerie fédérale ChF : Principe d’architecture 10 (AP10) de l’architecture API de la Confédération
#Idempotence #DistributedSystems #Microservices #SoftwareArchitecture #Kafka #RabbitMQ #SystemDesign #Resilience #SoftwareEngineering